Ahorrando $23,640 optimizando queries

Antes de que empezara a hacer cambios en la infraestructura, la regla era simplemente subir un nivel en el tamaño del servidor, cada vez que había un pico y se confirmaba que la base de datos era la causa, se aumentaba el tamaño del servidor y en algún momento teníamos una sola instancia 8xlarge para nuestra base de datos principal.

En el pasado no se había implementado ningún sistema de logging y las acciones se basaban únicamente en el uso de recursos. Empezamos a tener una mejor visibilidad de nuestros servicios después de implementar Datadog en AWS, establecimos alertas para el uso de recursos y también habilitamos los logs de la base de datos, incluyendo los slow queries logs.
Al principio estábamos revisando los logs en cloudwatch cuando se generaba una alerta, lo que hacía un poco lento darnos cuenta de lo que realmente estaba sucediendo, me alegro de que en algún momento introduje Grafana como una alternativa para sacar informes en tiempo real y así poder medir la el comportamiento de nuestro sitio web. Después de unos días de la implementación descubrí que Grafana tiene una comunidad que comparte sus dashboards y simplemente copiando los ids puedes configurar el mismo dashboard.
Utilicé este para Cloudwatch logs
El dashboard te permite filtrar por los grupos de logs y por defecto lo configuré para que mostrara los slow queries logs, con esto se puede encontrar rápidamente los queries y también el origen de ellos ya que este reporte te da toda la información relacionada al query, el usuario, host, tiempo de ejecución y por supuesto el query completo.

Cuando se detecta un slow query el proceso es simple, encontrar la parte del código que lo está ejecutando, intentar optimizar el query ya sea cambiando la estructura o agregando índices, a veces también es necesario cambiar la lógica detrás del query para mejorarlo.
Este es un trabajo diario, tan pronto como detectamos queries que impactan el performance intentamos arreglarlo, como consecuencia de esto nuestra base de datos principal es una instancia mucho más pequeña y como se puede ver en el siguiente gráfico, la mayor parte del tiempo está por debajo del 10% de uso, permitiéndonos reducirlo aún más.
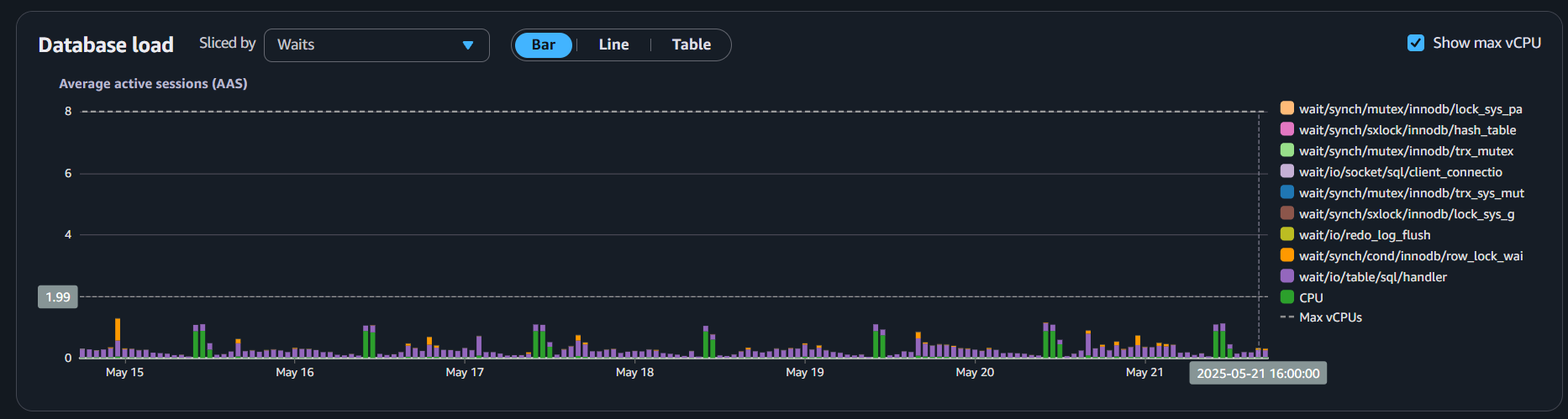
También implementamos read replicas que manejan todos los select queries y reportes, quitando todo ese procesamiento de la instancia principal, y probablemente podamos reducirla también ya que el uso de cpu está siempre por debajo del 25%.
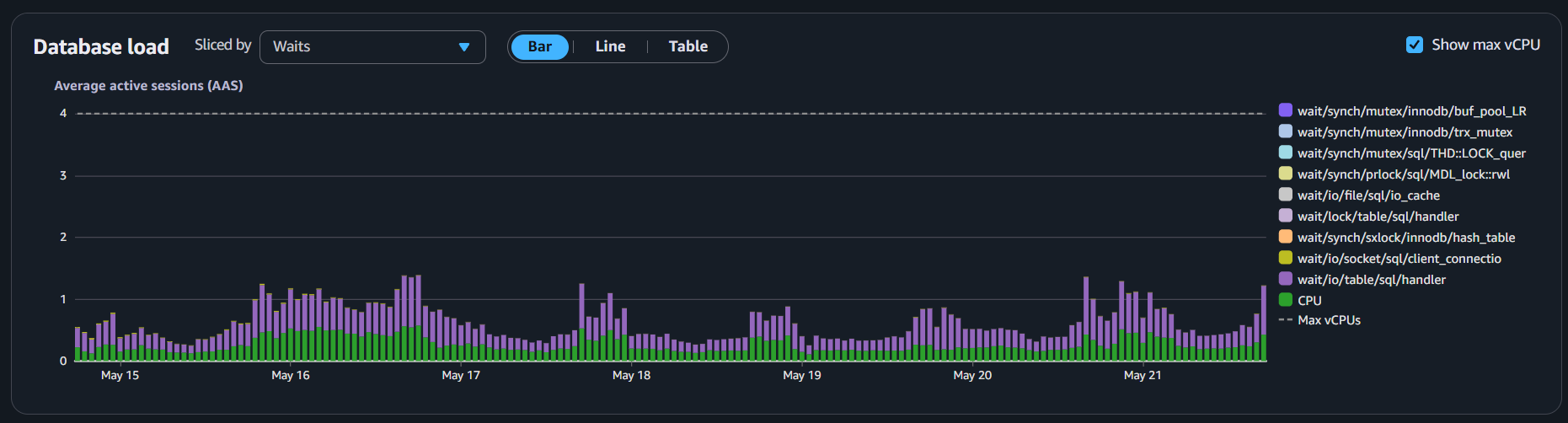
Implementando estas herramientas ahora medir la salud general de nuestras bases de datos es más fácil, al mismo tiempo que podemos mejorar la velocidad, resiliencia y tiempo de respuesta.
Recibe contenido de calidad suscribiendote al newsletter, Cero Spam!!