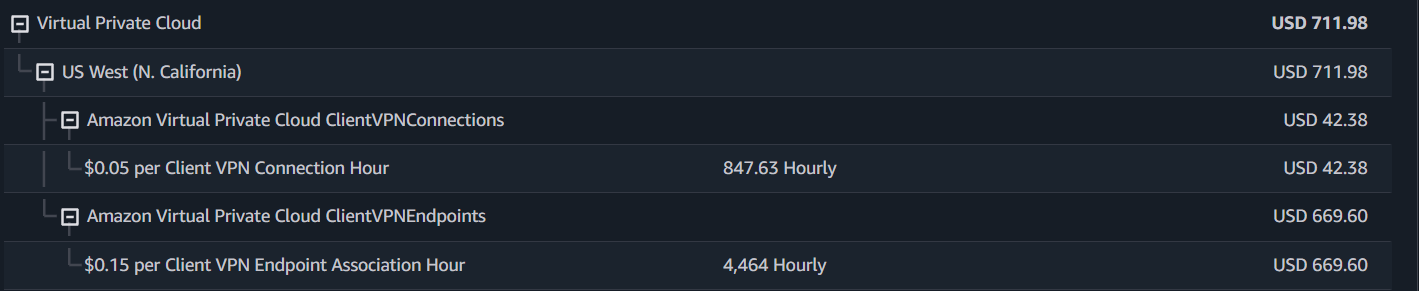
Una de las primeras implementaciones de infraestructura que hice fue migrar la app principal de 3 servidores EC2 a ECS Fargate. Este fue el resultado de una conversación que tuve con el CTO cuando propuse ayudar con algunas tareas de DevOps.
Hubo varias razones que me impulsaron a comprometerme con esto. Primero, cuando comencé a trabajar para la compañía tuve acceso a AWS y descubrí que nuestros servidores estaban sobredimensionados y estábamos pagando demasiado por ellos. El uso de CPU del servidor principal estaba por debajo del 5%, este se encargaba de ejecutar un montón de trabajos cron, y los otros 2 servidores estaban por debajo del 2% en uso de CPU. La memoria RAM no era diferente.