How I helped a company to avoid paying $100k on Aurora RDS

Late in 2023, AWS informed us that our Aurora servers needed to be migrated due to the deprecation of MySQL Community major version 5.7, recommending a migration to major version 8.0.
[!cite] AWS Announcement
[!note] Check how companies are unaware of these costs and how this could be impacting your billing: AWS Billing spike due to RDS Extended Support
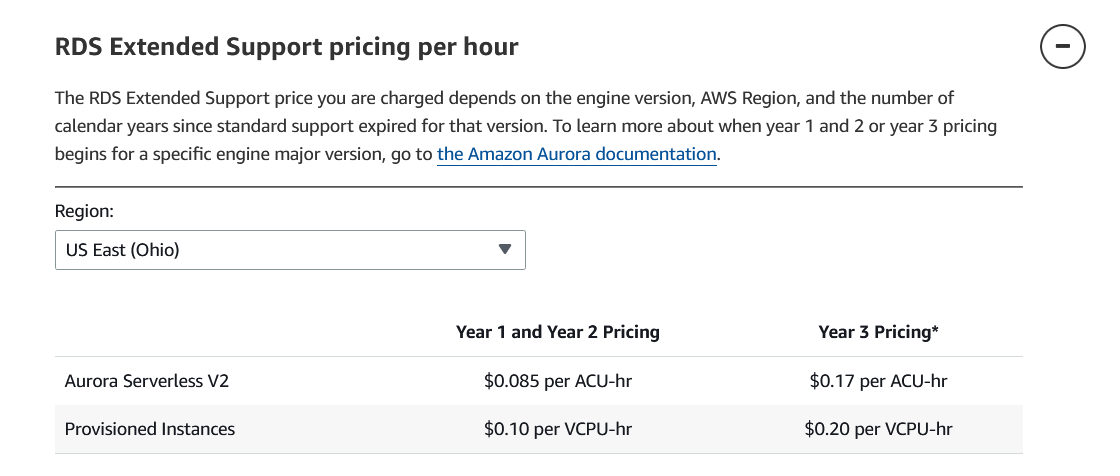
That day during our stand-up meeting, the Scrum Master and the CTO assigned me the task of evaluating the impact of this notification. I immediately raised my concern about the costs the company would incur if we didn’t meet the deadline. Initially, it didn’t seem like much - $0.1 per VCPU -, so I decided to invest that day in compiling all the numbers to ensure everyone understood the impact of this notification.
The following day, during my turn in the stand-up meeting, I explained the numbers to the team, outlining all the services involved and my action plan to complete the migration. The following table shows the additional costs we would have paid every month:
| Instance Type | Instances | V-CPUs | Additional Cost Monthly 1st & 2nd Year | Additional Cost Monthly 3rd Year |
|---|---|---|---|---|
| db.r5.4xlarge | 2 | 32 (16x2) | $2,380 ($0.1 x 32VCPU x 744H) | $4,761.6 ($0.2 x 32VCPU x 744H) |
| db.t3.small | 12 | 24 (2x12) | $1,785.6 ($0.1 x 24VCPU x 744H) | $3,571.2 ($0.2 x 24VCPU x 744H) |
| Total | 56 | $4,165.6 | $8,332.8 | |
| Total Yearly | $49,987.2 | $99,974.4 |
This was 2 and 3 times the monthly budget for databases at that time. After the numbers were discussed, I got the green light, and migrating became a high priority.
As you can see by the number of instances, there were many engines to migrate, and my action plan was the following:
- Start migrating lower environments first (DEV, QA, STAGING, PRE-PROD).
- Migrate one engine daily.
- Back up every engine before migrating.
- Notify IT members about lower environment migrations before migrating any engine.
- After the migration:
- Measure downtime.
- Check if there were any incidents after migrating.
- Check application logs related to every migrated engine.
- Check CPU and RAM usage.
- If all was good, start migrating another lower environment engine.
- After migrating all the lower environment engines:
- Wait 1 week before migrating production.
- Check if there were any incidents after migrating.
- Check application logs related to every migrated engine.
- Check CPU and RAM usage.
- If all was good:
- Define a timeframe when we can proceed, reducing the impact of the migration to the minimum.
- Notify board members about the migration and the estimated downtime.
- Start migrating production services.
After all the migrations before moving forward with production, I was pretty confident with all my notes and the steps needed to complete the task seamlessly. Indeed, the migration was successful, but we encountered two issues after the migration:
- The RDS engine CPU usage increased around 15 - 20%, with some spikes.
- This was resolved after cleaning up a bunch of legacy queries that were working differently with the new engine version.
- Late that night, the data analysis team complained that the binary logs were not replicating to a third-party big data application.
- Despite the late hour and their impatience for something we could solve the next day (as they were not evaluating data at that moment), this was easily fixed by creating the missing parameter group, and replication was resumed.
This was a great experience with databases, and I hope in the near future we can have some hands-on videos explaining how to perform the migrations.
Get quality content updates subscribing to the newsletter, Zero Spam!